When working with AI tools, every word you type becomes tokens tiny pieces of text the system processes. Both your prompt and the AI’s response consume these tokens. If your prompt is vague or incomplete, the AI may misunderstand you, generate the wrong output, or ask you to clarify. And each extra message means more tokens disappearing from your balance.
Clear and detailed prompts prevent confusion, reduce rewrites, and help you get the right answer in one shot. That’s how you save tokens without compromising quality.
Why Vague Prompts Are Token Vampires
Picture this: You’re at a restaurant. You tell the waiter, “Food, please.”
The waiter confidently brings you… a pizza loaded with anchovies. Definitely not what you had in mind.
That’s what happens with a vague prompt. You give too little information, so the AI takes a wild guess. And AI guesses can be bold like your uncle’s fashion sense: creative, but rarely correct.
Then you clarify, correct, complain, and send more messages. Each of those?
More tokens gobbled up.
A clear prompt is like saying:
“Medium-rare steak, fries on the side, no onions.”
Specific. Clear. Zero confusion.
Exact result on the first try.
Tokens saved: priceless.!!!
The Ice Cream Problem
If you write:
“I want ice cream.”
The AI doesn’t know if you want chocolate, vanilla, double scoop, single scoop, in a waffle cone, a cup, or directly from a 5 liter tub after a long Monday.
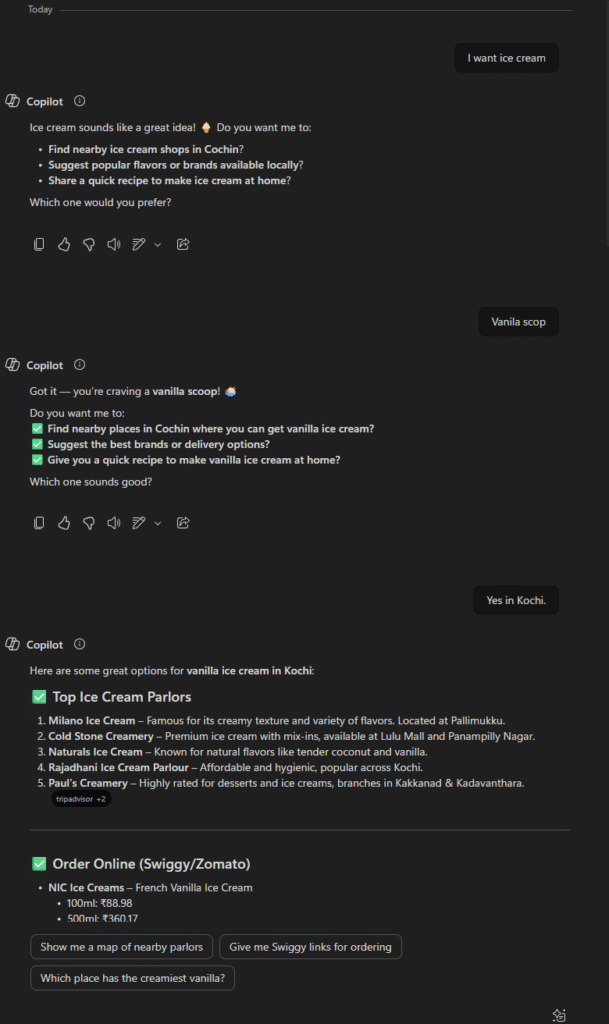
But if you say:
“I want a double scoop of chocolate and vanilla in a waffle cone in Kochi.”
The AI gets it right immediately. Fewer guesses. Fewer corrections. Fewer tokens spent.
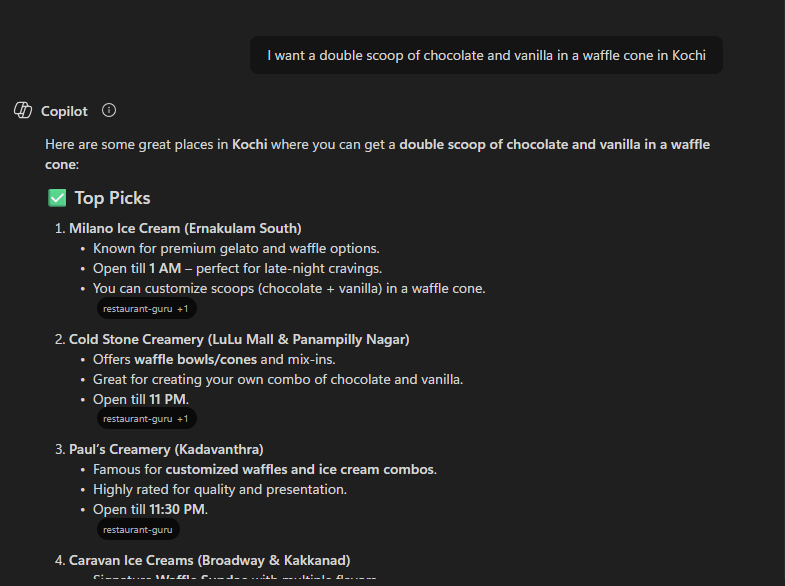
This screenshot proves this clearly:
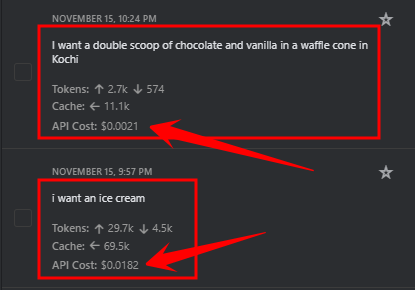
Clear prompt: Tokens: ~2.7k and API Cost: $0.0021
Vague prompt: Tokens: ~29.7k and API Cost: $0.0182
The vague prompt cost over 7 times more than the clear one.
Why such a big difference?
Because the unclear prompt forced the AI to guess, over-explain, and generate unnecessary details. increasing output tokens, which are the most expensive part of a conversation.
Clear prompt -> direct answer -> fewer tokens -> lower cost.
Example 2: Image Generation
Image prompts need crystal clarity.
Vague prompt:
Generate a dog picture
The AI might give you a puppy, a wolf, a bulldog in sunglasses, or a golden retriever doing yoga. You’ll spend tokens fixing it.
Clear prompt:
Generate an image of a golden retriever puppy sitting on green grass with soft afternoon sunlight in the background
Details eliminate surprises. And token waste.
Example 3: Coding Requests
When developers write classes or functions, they should always include XML summary comments. These summaries explain what the code does, what goes in, what comes out, and what errors may happen.
Why is this important?
Because when your code has no explanation, the AI is forced to guess the purpose — and trust me, AI guesses in code can be very dangerous and very expensive in tokens.
It’s like handing someone a toolbox and saying:
“Fix this.”
Fix what? Why? How? Should it also make coffee?
Without context, the AI may rewrite logic incorrectly or misunderstand your intent.
Then you spend more messages fixing it, which means more tokens.
XML summaries give the AI clear instructions even when you’re not explaining the code yourself.
Here is a example:
<span class="line"><span style="color: #6A9955">/// <summary></span></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #6A9955">/// Retrieves employee details from the database using the employee ID.</span></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #6A9955">/// This helps future developers and AI tools understand what this method is meant to do.</span></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #6A9955">/// </summary></span></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #6A9955">/// <param name="employeeId">The unique ID of the employee you want to look up.</param></span></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #6A9955">/// <returns></span></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #6A9955">/// The employee's details if found. Returns null if the employee does not exist.</span></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #6A9955">/// </returns></span></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #6A9955">/// <exception cref="DatabaseException"></span></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #6A9955">/// Thrown if the database connection fails or encounters an issue.</span></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #6A9955">/// </exception></span></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #9CDCFE">public</span>
<span style="color: #D4D4D4"> </span>
<span style="color: #9CDCFE">async</span>
<span style="color: #D4D4D4"> </span>
<span style="color: #9CDCFE">Task</span>
<span style="color: #D4D4D4"><</span>
<span style="color: #9CDCFE">EmployeeDetails</span>
<span style="color: #D4D4D4">?> </span>
<span style="color: #DCDCAA">GetEmployeeDetailsAsync</span>
<span style="color: #D4D4D4">(</span>
<span style="color: #9CDCFE">int</span>
<span style="color: #D4D4D4"> </span>
<span style="color: #9CDCFE">employeeId</span>
<span style="color: #D4D4D4">)</span></span>
<span class="line"><span style="color: #D4D4D4"> {</span></span>
<span class="line"><span style="color: #D4D4D4"> ...</span></span>
<span class="line"><span style="color: #D4D4D4"> }</span></span>
<span class="line"></span><span class="line"><span style="color: #6A9955">/// <summary></span></span>
<span class="line"><span style="color: #6A9955">/// Model representing basic employee information</span></span>
<span class="line"><span style="color: #6A9955">/// </summary></span></span>
<span class="line"><span style="color: #9CDCFE">public</span>
<span style="color: #D4D4D4"> </span>
<span style="color: #9CDCFE">record</span>
<span style="color: #D4D4D4"> </span>
<span style="color: #9CDCFE">EmployeeDetails</span></span>
<span class="line"><span style="color: #D4D4D4">{</span></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #6A9955">/// <summary></span></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #6A9955">/// Unique employee identifier</span></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #6A9955">/// </summary></span></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #9CDCFE">public</span>
<span style="color: #D4D4D4"> </span>
<span style="color: #9CDCFE">int</span>
<span style="color: #D4D4D4"> </span>
<span style="color: #9CDCFE">Id</span>
<span style="color: #D4D4D4"> { </span>
<span style="color: #9CDCFE">get</span>
<span style="color: #D4D4D4">; </span>
<span style="color: #9CDCFE">init</span>
<span style="color: #D4D4D4">; }</span></span>
<span class="line"></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #6A9955">/// <summary></span></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #6A9955">/// Full name of the employee</span></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #6A9955">/// </summary></span></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #9CDCFE">public</span>
<span style="color: #D4D4D4"> </span>
<span style="color: #9CDCFE">string</span>
<span style="color: #D4D4D4"> </span>
<span style="color: #9CDCFE">Name</span>
<span style="color: #D4D4D4"> { </span>
<span style="color: #9CDCFE">get</span>
<span style="color: #D4D4D4">; </span>
<span style="color: #9CDCFE">init</span>
<span style="color: #D4D4D4">; } = </span>
<span style="color: #9CDCFE">string</span>
<span style="color: #D4D4D4">.</span>
<span style="color: #9CDCFE">Empty</span>
<span style="color: #D4D4D4">;</span></span>
<span class="line"></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #6A9955">/// <summary></span></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #6A9955">/// Department name where the employee works</span></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #6A9955">/// </summary></span></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #9CDCFE">public</span>
<span style="color: #D4D4D4"> </span>
<span style="color: #9CDCFE">string</span>
<span style="color: #D4D4D4"> </span>
<span style="color: #9CDCFE">Department</span>
<span style="color: #D4D4D4"> { </span>
<span style="color: #9CDCFE">get</span>
<span style="color: #D4D4D4">; </span>
<span style="color: #9CDCFE">init</span>
<span style="color: #D4D4D4">; } = </span>
<span style="color: #9CDCFE">string</span>
<span style="color: #D4D4D4">.</span>
<span style="color: #9CDCFE">Empty</span>
<span style="color: #D4D4D4">;</span></span>
<span class="line"></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #6A9955">/// <summary></span></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #6A9955">/// Official email address of the employee</span></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #6A9955">/// </summary></span></span>
<span class="line"><span style="color: #D4D4D4"> </span>
<span style="color: #9CDCFE">public</span>
<span style="color: #D4D4D4"> </span>
<span style="color: #9CDCFE">string</span>
<span style="color: #D4D4D4"> </span>
<span style="color: #9CDCFE">Email</span>
<span style="color: #D4D4D4"> { </span>
<span style="color: #9CDCFE">get</span>
<span style="color: #D4D4D4">; </span>
<span style="color: #9CDCFE">init</span>
<span style="color: #D4D4D4">; } = </span>
<span style="color: #9CDCFE">string</span>
<span style="color: #D4D4D4">.</span>
<span style="color: #9CDCFE">Empty</span>
<span style="color: #D4D4D4">;</span></span>
<span class="line"><span style="color: #D4D4D4">}</span></span>Even a beginner can understand what this method is supposed to do.
So when you ask the AI:
“Fix the bug in GetEmployeeDetailsAsync”
The AI doesn’t guess. it already knows the purpose.
Clear summary → less confusion → fewer corrections → fewer tokens used.
Understanding Tokens
A token is a tiny piece of text. AI reads and writes using tokens.
There are two types of tokens you pay for:
- Input Tokens
These are the tokens in your prompt.
Long prompt = more input tokens.
- Output Tokens
These are the tokens in the AI’s response.
Long answer = more output tokens.
Both count toward your usage and cost.
This means:
- A vague prompt: AI gives a long explanation, more output tokens wasted
- A clear prompt: AI gives a focused answer, fewer output tokens
If your prompt is unclear, the AI may generate:
- long explanations
- multiple suggestions
- extra details you didn’t ask for
That’s more output tokens spent… and more money gone.
Think of it like calling customer support:
If you’re vague, they explain everything from A to Z.
If you’re clear, they give the exact answer and end the call faster (and cheaper).
Hidden Token Traps
- Asking for corrections too often (AI reprocesses the whole chat)
- Repeating long code blocks
- Sending multiple small prompts instead of one detailed one
- Switching topics in the same conversation
- Asking for long explanations when you only need a short answer
Avoid these, and your token usage drops instantly.
Practical Ways to Save Tokens
- Write one complete prompt instead of many small ones.
- Don’t resend long code — paste once.
- Use simple, direct language.
- Ask AI to “give only the code” to reduce output tokens.
- Request small changes instead of full rewrites.
- Ask for summaries instead of detailed breakdowns.
- Use detailed image prompts to avoid retries.
- Use “Continue” when answers cut off.
- Start a new chat for new topics.
Common Beginner Mistakes
- Repeating the same vague question
- Asking “Are you there?”
- Sending giant code blocks repeatedly
- Mixing unrelated topics in one chat
- Writing prompts with missing details
Fix these, and your token usage improves automatically.
Conclusion
Saving tokens isn’t about writing short prompts —
it’s about writing clear, complete prompts.
The clearer your instructions, the fewer follow-up messages you need.
That means fewer misunderstandings and fewer tokens burned.
Good prompts give good outputs.
Clear prompts save time.
Complete prompts save tokens.