vTSafeKernelInvoker is a lightweight .NET extension for Semantic Kernel that introduces the method InvokePromptFunctionUsingCustomizedKernelAsync. This method helps reduce AI service token usage and cost by avoiding unnecessary AI post-processing of plugin results.
Curious about Semantic Kernel? Explore the official overview here: https://learn.microsoft.com/en-us/semantic-kernel/overview/
Why Use This Package?
When using standard Semantic Kernel methods like InvokePromptAsync or GetChatMessageContentAsync (via IChatCompletionService) etc, the plugin result is sent back to the AI for additional processing such as formatting, filtering, or styling. This increases output tokens and raises costs—especially for large responses.
In contrast, InvokePromptFunctionUsingCustomizedKernelAsync bypasses this extra step. It returns the plugin output directly to the user, keeping output token usage minimal regardless of the data size. This makes it ideal for performance-critical or cost-sensitive applications.
How It Works
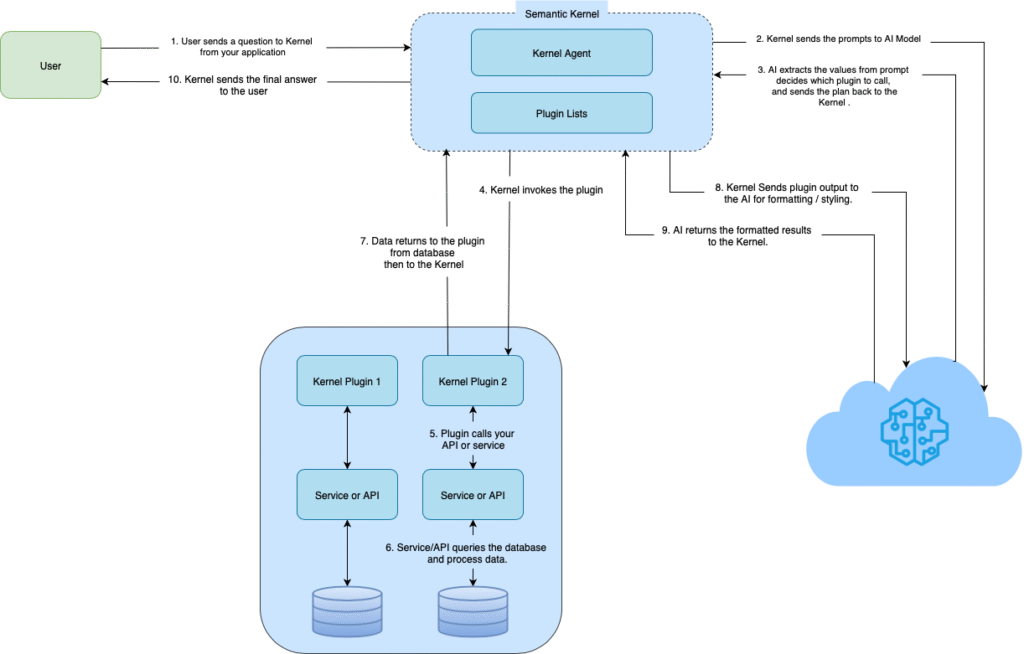
Standard Semantic Kernel Flow:
- Send prompt to AI
- AI plans which plugin to call
- Plugin executes and returns data
- Plugin result sent back to AI for formatting (Extra tokens!)
- AI returns formatted response
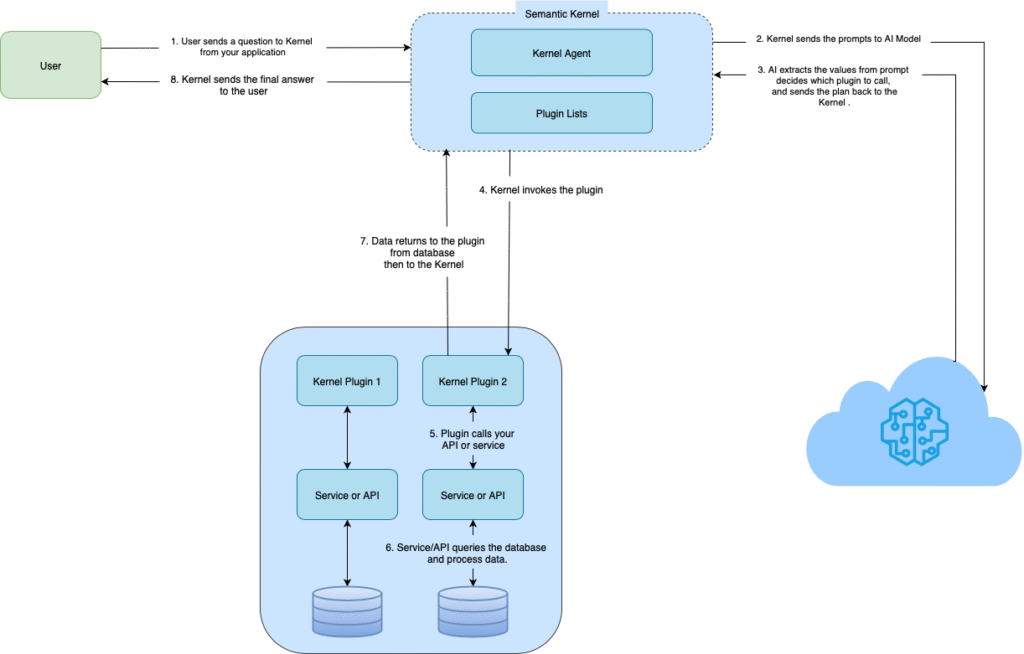
vTSafeKernelInvoker Flow:
- Send prompt to AI
- AI plans which plugin to call
- Plugin executes and returns data
- Result returned directly to user (No extra tokens!)
Token Usage: Input and output tokens are charged only for deciding which plugin function to call. Once the plugin executes, no additional tokens are consumed regardless of the data size returned.
Note: Token usage for planning will increase if you have more plugins, functions, or parameters in your kernel, as the AI needs more context to make decisions.
Key Benefits
- Lower Costs: Up to 85% reduction in token usage
- Faster Response: No extra AI processing step
- Same Functionality: Works with your existing Semantic Kernel plugins
- Predictable Costs: Tokens are only charged for plugin planning, not for data size returned
Real Cost Comparison (if using GPT-3.5-Turbo)
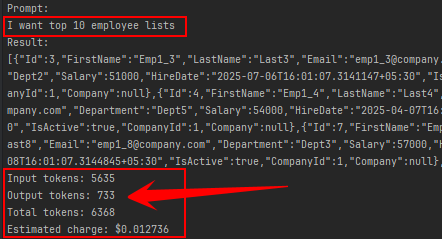
Example: “Get top 10 employees”
using Kernel’s standard method InvokePromptAsync :
- Input tokens: 5635
- Output tokens: 733
- Total tokens: 6368
- Estimated charge: $0.00392
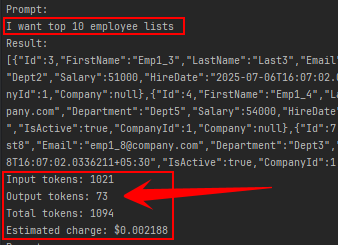
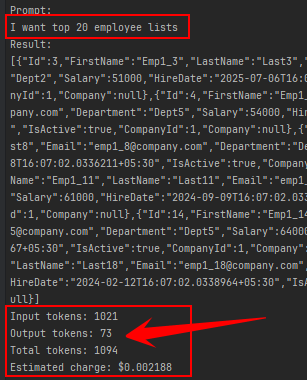
using this package’s method InvokePromptFunctionUsingCustomizedKernelAsync :
- Input tokens: 1021
- Output tokens: 73
- Total tokens: 1094
- Estimated charge: $0.00062
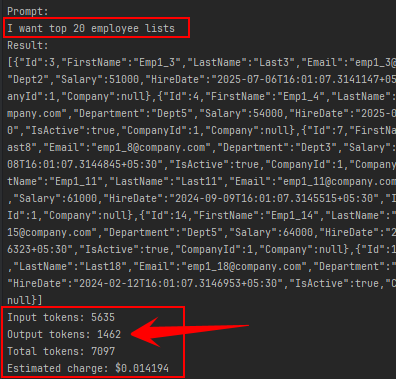
Example: “Get top 20 employees”
using Kernel’s standard method InvokePromptAsync :
- Input tokens: 5635
- Output tokens: 1462
- Total tokens: 7097
- Estimated charge: $0.014194
using this package’s method InvokePromptFunctionUsingCustomizedKernelAsync :
- Input tokens: 1021
- Output tokens: 73
- Total tokens: 1094
- Estimated charge: $0.00062
Notice: With larger datasets, savings increase dramatically!
Installation
dotnet add package vTSafeKernelInvokerBasic Usage
using vT.SafeKernelInvoker;
// Instead of this expensive method:
// var result = await kernel.InvokePromptAsync("Get top 10 employees");
// Use this cost-effective method:
var result = await kernel.InvokePromptFunctionUsingCustomizedKernelAsync(
"Get top 10 employees"
);
// Result is raw plugin output - no AI formatting, maximum savings!When Should You Use This?
Perfect for:
- Data retrieval operations
- Database queries
- Report generation
- API calls that return structured data
- Cost-sensitive applications
- Large data responses
Not ideal for:
- When you need AI to format or style the output
- Creative writing tasks
- Simple conversational responses
Getting Started
- Install the package
- Add
using vT.SafeKernelInvoker; - Replace
InvokePromptAsyncwithInvokePromptFunctionUsingCustomizedKernelAsync - Enjoy dramatically lower costs!
Example Code
using vT.SafeKernelInvoker;
using Microsoft.SemanticKernel;
using Microsoft.Extensions.DependencyInjection;
var builder = Kernel.CreateBuilder().AddAzureOpenAIChatCompletion(
deploymentName: "YOUR_DEPLOYMENT_NAME",
endpoint: "YOUR_AZURE_ENDPOINT",
apiKey: "YOUR_API_KEY"
);
builder.Plugins.AddFromType<YourPlugin>();
//builder.Services.AddScoped<IYourService, YourService>(); //If you want to use a service layer
var kernel = builder.Build();
var result = await kernel.InvokePromptFunctionUsingCustomizedKernelAsync(
"Get top 10 employees"
);
Console.WriteLine(result);To create a Kernel Plugin class, as shown in the code snippet builder.Plugins.AddFromType(), refer to the official documentation here: https://learn.microsoft.com/en-us/semantic-kernel/concepts/plugins/?pivots=programming-language-csharp
Diagram
Semantic Kernel’s standard diagram
vTSafeKernelInvoker diagram :
Screenshots of token usage:
Perfect for: Developers who want to optimize AI costs without sacrificing functionality.
If you have any more questions or need further clarification, feel free to ask!
One response to “vTSafeKernelInvoker – Efficient Semantic Kernel Plugin Execution Without Extra AI Token Costs, Especially for Large Output Data”
[…] more about that package : https://wisecodes.venuthomas.in/2025/08/09/vtsafekernelinvoker-efficient-semantic-kernel-plugin-exec… […]